前言
参考内容:
结构:
- 概述
- 快速上手与部署
- 运行时架构
- DataStreamAPI
- 窗口
- 水位线
- 处理函数
- 状态管理
- 容错机制
- FlinkSQL
扫盲
Flink 是什么:一个框架和分布式处理引擎,对无界和有界数据流进行有状态计算;
核心目标:数据流上的有状态计算。
特点:
- 高吞吐量、低延迟;
- 结果准确性,提供事件时间和处理时间语义,保证一致结果;
- 精确一次(exactly-one)的状态一致性保证;
- 可以和 Kafka、Hive、JDBC、HDFS、Redis 等结合使用;
- 高可用。
- Flink 分层 API:
- 最高层:SQL;
- 声明式领域专用语言:Table API,表对象(用得不多,一般都用 SQL 更方便些);
- 核心 APIs:DataStream/DataSet,一个负责流计算,一个负责批处理,但在高版本 Flink 中都用 DataStream 了;
- 底层 APIs:处理函数,有状态流处理。
- 名词:
- 流处理?批处理?
- 流处理:流处理相反是为了解决
实时计算或是近实时计算问题; - 批处理:批处理一般是解决
离线计算数据量大,计算时间慢的问题,先拿到本地。 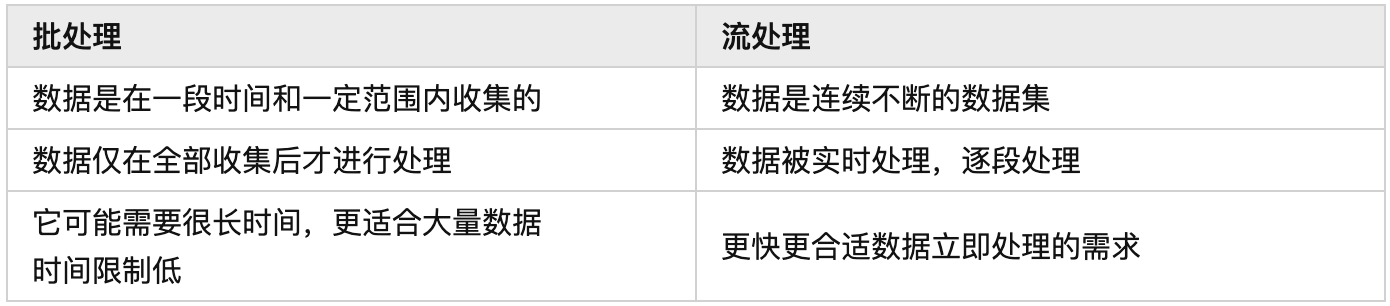
- 流处理:流处理相反是为了解决
- 无界流?有界流?
- 无界流:只定义流的开始,没有定义流的结束,一直产生数据,
数据需要被立即处理; - 有界流:流有开始也有结束,可以在获取到所有数据后再
统一处理,另外,其顺序可以被排序,所以不需要有序获取,有界流处理通常称为“批处理”。
- 无界流:只定义流的开始,没有定义流的结束,一直产生数据,
- 无状态?有状态?
- 有状态:将流处理需要的额外数据记录下来,称为“状态,对数据进行处理后,更新状态。可以是
中间计算结果,也可以是数据本身。Flink 本身就可以存储这些状态到内存,然后定期持久化(备份)。
- 有状态:将流处理需要的额外数据记录下来,称为“状态,对数据进行处理后,更新状态。可以是
- Flink vs SparkStreaming?
- Spark:
批处理,“微批次”处理(攒几秒的数据,然后再处理这几秒内的数据),基于 RDD 数据模型; - Flink:
流处理,基于数据流数据模型,以及事件序列,是标准的流执行模式。
- Spark: